Benchmark SER: Classical ML vs Deep Learning — Ai thắng và tại sao?
Tại sao cần benchmark đa mô hình?
Khi bắt đầu dự án Speech Emotion Recognition, câu hỏi đầu tiên là: nên dùng mô hình gì? Thay vì đoán mò, tôi quyết định xây dựng một framework chạy tất cả các ứng viên tiêu biểu và để số liệu thực nói chuyện. Kết quả thật sự bất ngờ ở một số điểm.
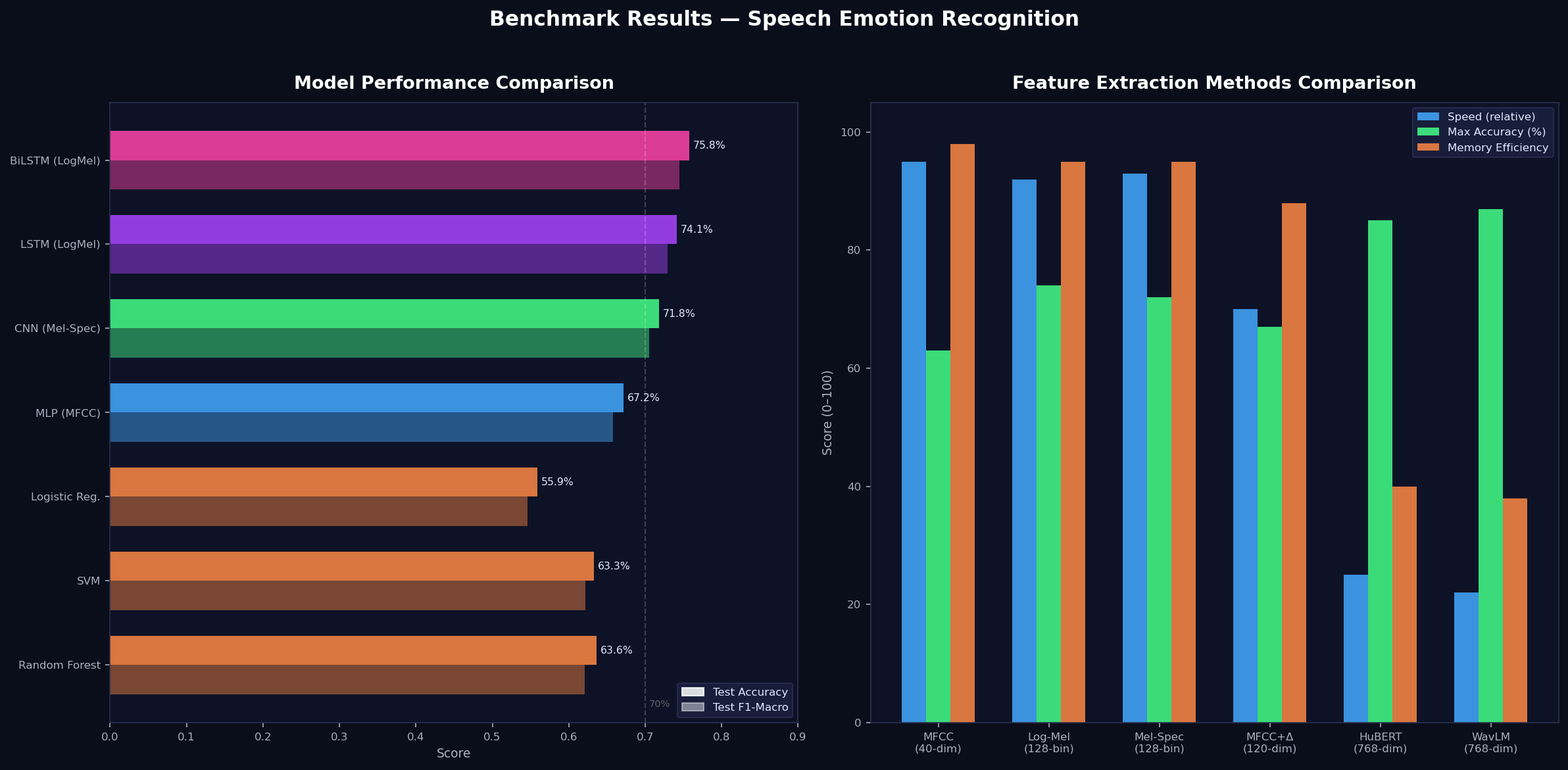
Kết quả tổng quan
Pipeline Feature Test Acc Test F1 Train Time BiLSTM Log-Mel ~75.8% 0.745 ~25 min LSTM Log-Mel ~74.1% 0.729 ~20 min CNN (ResNet18) Mel-Spec ~71.8% 0.705 ~18 min MLP MFCC ~67.2% 0.658 ~8 min Random Forest MFCC 63.6% 0.621 ~1.5 min SVM MFCC 63.3% 0.622 ~1.6 min Logistic Reg. MFCC 55.9% 0.546 ~1.8 minPhân tích sâu: Tại sao BiLSTM thắng?
1. Cảm xúc là chuỗi thời gian, không phải snapshot
MFCC flat vector (80 chiều) "nén" toàn bộ 3 giây âm thanh thành một vector cố định — mất hoàn toàn thông tin về diễn biến theo thời gian. Giọng "giận dữ" thường có pattern: bắt đầu bình thường → tăng dần → peak năng lượng. CNN và LSTM/BiLSTM giữ nguyên chiều thời gian (T, F), cho phép học patterns này.
BiLSTM có lợi thế thêm so với LSTM: context 2 chiều. Khi đọc từ trái sang phải VÀ từ phải sang trái, nó capture được ngữ cảnh đầy đủ hơn — ví dụ, pitch ở cuối câu ảnh hưởng đến cách hiểu pitch ở đầu câu.
2. Log-Mel > MFCC cho deep learning
MFCC tốt cho classical ML vì nó compressed — chỉ giữ lại những thông tin quan trọng nhất. Nhưng DL models có thể học được những pattern tinh tế hơn từ full spectrogram. Log-Mel (128 bins × T frames) chứa nhiều thông tin tần số hơn, cho phép CNN/LSTM phân biệt được những sắc thái mà MFCC bỏ qua.
3. CNN tốt nhưng thiếu temporal modeling
CNN (ResNet18) xử lý spectrogram như ảnh 2D — nó giỏi nhận ra texture (patterns tần số-thời gian cục bộ) nhưng không explicit model sequence. LSTM/BiLSTM ngược lại — explicit track trạng thái qua thời gian. Trong thực tế, best of both worlds thường là CNN-LSTM hybrid, nhưng tôi chưa implement trong version này.
Random Forest: "Chậm mà chắc" hay thật sự tệ?
63.6% có vẻ thấp, nhưng nhìn vào trade-off:
- Training time: 1.5 phút vs. 25 phút của BiLSTM
- Không cần GPU: chạy tốt trên CPU
- Interpretable: feature importance cho biết MFCC coefficients nào quan trọng nhất
- Ít hyperparameters: dễ tune, ít overfitting với dataset nhỏ
Cho production system nhỏ không cần real-time, RF vẫn là lựa chọn hợp lý. Với dataset lớn hơn nhiều, khoảng cách sẽ nới rộng hơn.
Tác động của Data Augmentation
Augmentation cho thấy cải thiện nhất quán ~2–5% F1 trên hầu hết pipelines:
- CNN + Mel-Spec: +3.2% F1 với SpecAugment
- LSTM + Log-Mel: +2.8% F1
- RF: gần như không thay đổi (augmentation không giúp classical ML nhiều)
SpecAugment hiệu quả nhất trong số các kỹ thuật thử nghiệm. Speed perturbation và pitch shift cũng giúp nhưng chậm hơn đáng kể vì xử lý ở waveform level.
So sánh Feature Extraction Methods
Một nhận xét thú vị: Log-Mel và Mel-Spec cho kết quả gần giống nhau (chênh lệch <1%). Sự khác biệt chính là ở scale (log vs. dB) — trong thực tế, cả hai đều capture cùng một thông tin. Nếu phải chọn, Log-Mel thường ổn định hơn trong training.
Bài học rút ra
- Temporal features quan trọng hơn model complexity: Chuyển từ flat MFCC sang temporal Log-Mel đã cho lợi ích lớn hơn là chuyển từ RF sang CNN với cùng features.
- Feature caching là bắt buộc: Không có cache, việc iterative experiment sẽ cực kỳ chậm. Thiết kế cache strategy từ đầu, không phải sau.
- Baseline đơn giản trước, phức tạp sau: RF/SVM trong 1.5 phút cho 63% — biết điểm baseline này rất có giá trị trước khi đầu tư 25 phút training BiLSTM.
- Augmentation luôn giúp ích với deep learning, dù chỉ một vài %. Với dataset nhỏ, đây là "free lunch" đáng làm.
- Hydra + Lightning = reproducibility: Mỗi experiment được tracked đầy đủ, dễ reproduce sau nhiều tuần.
Bước tiếp theo
Kết quả hiện tại (~75.8% với BiLSTM) vẫn còn room để cải thiện:
- CNN-LSTM Hybrid: CNN extract local features, LSTM model temporal sequence
- Transformer/Attention: Self-attention có thể capture long-range dependencies tốt hơn LSTM
- HuBERT + Fine-tuning: SSL pretrained models có tiềm năng đạt 85%+ với fine-tuning đúng cách
- Ensemble: Combine predictions từ nhiều models
- Larger dataset: Thu thập thêm dữ liệu tiếng Việt — đây có lẽ là leverage point cao nhất
Framework đã được thiết kế để dễ dàng thêm model mới — chỉ cần thêm config yaml và implement Lightning module tương ứng.