Khi mô hình ngôn ngữ “hiểu ảnh” mà không cần huấn luyện đa phương thức

Trong vài năm gần đây, Large Language Models (LLMs) đã thể hiện khả năng suy luận cực kỳ ấn tượng trong các bài toán ngôn ngữ. Tuy nhiên, khi bước sang thị giác (computer vision), hầu hết các phương pháp hiện tại đều yêu cầu multimodal pretraining: huấn luyện lại mô hình với hàng tỷ cặp ảnh–văn bản, tiêu tốn tài nguyên khổng lồ.
Bài toán đặt ra là:
Liệu có cách nào giúp LLM “hiểu ảnh” mà không cần huấn luyện đa phương thức hay không
1. Vấn đề của các mô hình Vision–Language hiện nay
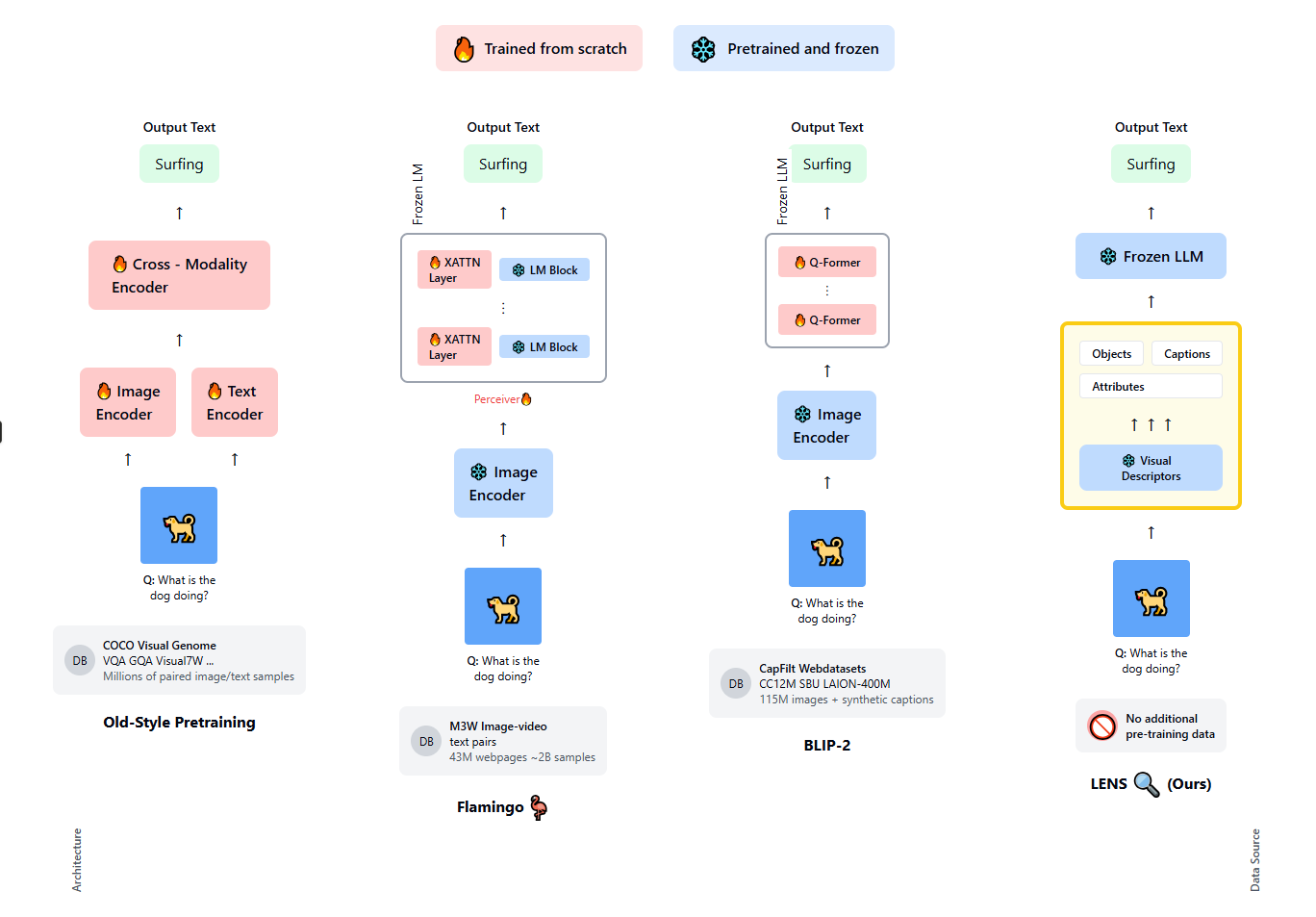
Các mô hình như Flamingo, BLIP-2 hay Kosmos đều đi theo một hướng chung:
-
Gắn vision encoder với LLM
-
Thêm cross-attention layers
-
Huấn luyện trên dataset ảnh–văn bản cực lớn
Ví dụ:
-
Flamingo cần ~2B image-text pairs
-
Chi phí huấn luyện lên tới hàng trăm nghìn TPU/GPU hours
Điều này dẫn tới 3 vấn đề lớn:
-
Compute cực đắt
-
Khó tái lập cho lab nhỏ
-
Khó tận dụng LLM mới nhất (GPT-4, Flan-T5-XXL, …)
Vậy giải pháp là gì
Thay vào đó, hãy đặt một câu hỏi đơn giản hơn:
Nếu LLM suy luận rất tốt trên văn bản, vậy tại sao không chuyển toàn bộ ảnh thành văn bản trước?
Ý tưởng cốt lõi
Chia bài toán thành hai tầng độc lập:
Vision Modules (đóng băng, pretrained)
-
Tag Module: phát hiện object (CLIP)
-
Attribute Module: mô tả thuộc tính (màu sắc, hình dáng, vật liệu…)
-
Intensive Captioning: sinh nhiều caption đa dạng (BLIP)
Mục tiêu: trích xuất càng nhiều thông tin thị giác càng tốt, không phụ thuộc câu hỏi
Reasoning Module (LLM đóng băng)
-
Nhận toàn bộ mô tả dạng text
-
Suy luận, trả lời câu hỏi vision & vision-language
Không có huấn luyện cross-modal. Không fine-tune. Không thêm dữ liệu.
Ví dụ với ảnh đầu vào mô hình tạo prompt dạng:
Tags: dog, surfboard, water, beach
Attributes: brown dog, blue shirt, small size
Captions:
- a dog riding a surfboard in the ocean
- a pug wearing a blue shirt surfing
Question: What is the dog wearing?
Answer:
Các bài toán phương pháp này giải quyết:
Bài toán 1: Object Recognition trong zero / few-shot
-
Nhận diện đối tượng trong ảnh
-
Không huấn luyện lại mô hình
-
Không giới hạn số class cố định
-
Hoạt động trong zero-shot / few-shot
Bài toán 2: Vision & Language Reasoning (VQA, Hateful Memes, Sentiment)
-
Trả lời câu hỏi dựa trên ảnh
-
Cần suy luận logic, không chỉ nhận diện object
-
Bao gồm:
-
VQA (câu hỏi tự nhiên)
-
OK-VQA (cần kiến thức bên ngoài)
-
Hateful Memes (kết hợp ảnh + chữ + sentiment)
-
Rendered-SST2 (hiểu cảm xúc văn bản trong ảnh
-
Result 1 – Zero-shot Object Recognition Results (Accuracy %)
Trong thiết lập zero-shot cho bài toán nhận diện đối tượng, mô hình CLIP với backbone ViT-L/14 đạt độ chính xác trung bình 71.7%, trong khi phiên bản ViT-H/14 đạt 76.6%. Mô hình của chúng tôi cho kết quả 72.3% với backbone ViT-L/14 và đạt mức cao nhất là 77.3% khi sử dụng backbone ViT-H/14, cho thấy hiệu năng cạnh tranh và cải thiện nhẹ so với CLIP tương ứng.
Result 2 – Zero-shot Vision & Language Results
Trên các bài toán thị giác–ngôn ngữ ở thiết lập zero-shot, Kosmos-1 (1.6B tham số huấn luyện) đạt 51.0% trên VQA v2, 67.1% trên Rendered-SST2 và 63.9% trên Hateful Memes (test-seen). Flamingo-9B (1.8B tham số) đạt 51.8% trên VQA v2, 44.7% trên OK-VQA và 57.0% trên Hateful Memes, trong khi Flamingo-80B (10.2B tham số) cải thiện lên 56.3% trên VQA v2 và 50.6% trên OK-VQA nhưng giảm còn 46.4% trên Hateful Memes. BLIP-2 (108M tham số) đạt kết quả cao nhất trên VQA v2 với 65.0% và đạt 45.9% trên OK-VQA. Mô hình của chúng tôi không sử dụng tham số huấn luyện bổ sung nhưng vẫn đạt 62.6% trên VQA v2, 43.3% trên OK-VQA, 82.0% trên Rendered-SST2 và 62.5% trên Hateful Memes (test-seen).

