Xây dựng Speech Emotion Recognition từ Scratch: Kiến trúc Multi-Pipeline ML Framework
Giới thiệu
Speech Emotion Recognition (SER) là bài toán phân loại cảm xúc của người nói dựa thuần túy vào tín hiệu âm thanh — không cần nội dung ngữ nghĩa. Nghe có vẻ đơn giản, nhưng thực tế đây là một trong những bài toán thú vị nhất trong AI vì nó đòi hỏi mô hình phải "nghe" được những thứ tinh tế: cao độ, nhịp điệu, năng lượng, trường độ âm.
Trong bài này, tôi sẽ chia sẻ toàn bộ quá trình xây dựng một multi-pipeline ML framework từ đầu — một hệ thống cho phép chạy và so sánh nhiều mô hình khác nhau một cách có hệ thống, từ Random Forest cổ điển đến BiLSTM hiện đại.
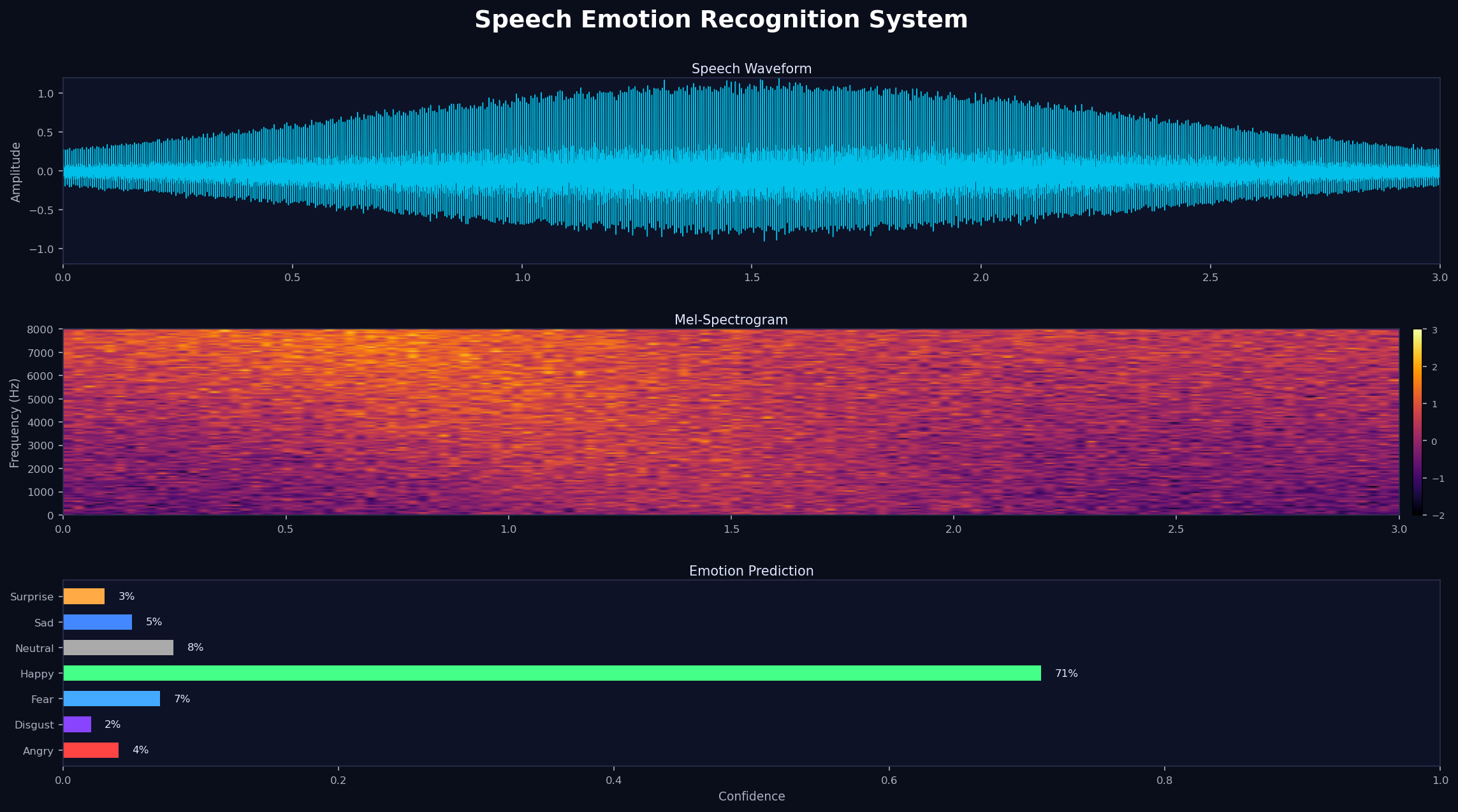
Bài toán và dữ liệu
Dataset là tập âm thanh tiếng Việt với 7 nhãn cảm xúc: Angry, Disgust, Fear, Happy, Neutral, Sad, Surprise. Mỗi file .wav dài khoảng 2–5 giây. Tỷ lệ chia: 70% train / 15% val / 15% test, stratified theo nhãn để đảm bảo phân phối đều.
Một thách thức lớn: dữ liệu âm thanh cần được chuẩn hóa trước khi trích xuất đặc trưng. Module AudioPreprocessor xử lý:
- Resample về 22.05kHz (hoặc 16kHz cho SSL models)
- Padding/truncation đồng đều về 3 giây
- RMS normalization để cân bằng volume
- Convert stereo → mono nếu cần
7 phương pháp trích xuất đặc trưng
Đây là phần quan trọng nhất — chọn cách biểu diễn âm thanh ảnh hưởng rất lớn đến kết quả:
1. MFCC (Mel-Frequency Cepstral Coefficients)
Phương pháp cổ điển nhất, mô phỏng cách tai người xử lý âm thanh. 40 hệ số MFCC + delta + delta-delta = 120 chiều. Nhanh (~22ms/sample), phù hợp cho classical ML.
2. Log-Mel Spectrogram
128 frequency bins theo thang Mel, apply log scale. Giữ nguyên chiều thời gian (T, 128) — lý tưởng cho CNN và RNN. Tốt hơn MFCC cho deep learning vì giữ được nhiều thông tin tần số hơn.
3. Mel-Spectrogram (dB scale)
Tương tự Log-Mel nhưng convert sang decibel. Cả hai đều tốt cho CNN; thực nghiệm cho thấy sự khác biệt nhỏ.
4 & 5. HuBERT và WavLM (Self-Supervised)
Các mô hình transformer pretrained trên hàng nghìn giờ audio. Output là dense embeddings 768-dim có ngữ nghĩa phong phú. Đắt về mặt tính toán nhưng tiềm năng accuracy cao nhất.
# Trích xuất HuBERT embeddings
from transformers import HubertModel
model = HubertModel.from_pretrained("facebook/hubert-base-ls960")
with torch.no_grad():
outputs = model(waveform)
embeddings = outputs.last_hidden_state.mean(dim=1) # (batch, 768)Kiến trúc Pipeline
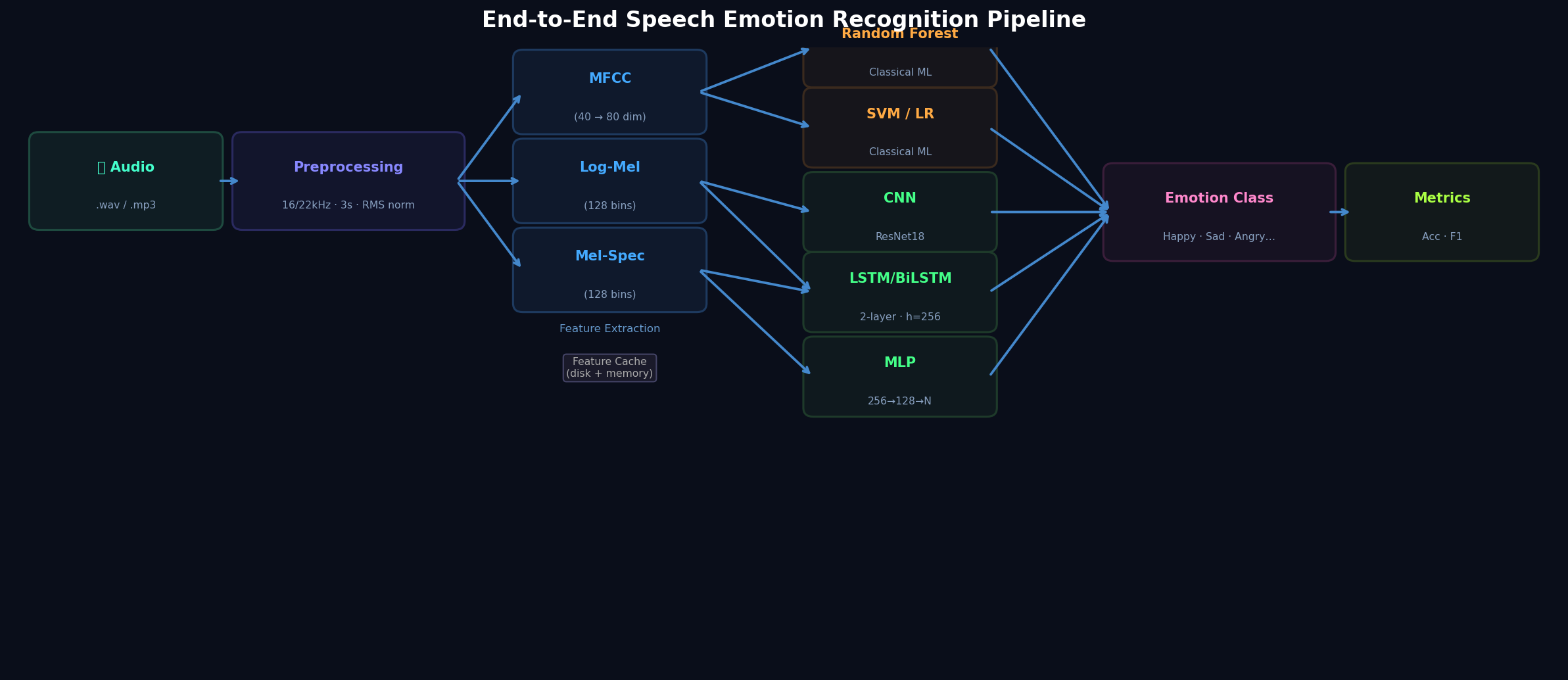
Framework được tổ chức theo pattern Strategy — mỗi pipeline là một combination của feature extractor + model. Base class BasePipeline định nghĩa interface chung:
class BasePipeline:
def run(self, cfg: DictConfig) -> dict:
data = self.load_data(cfg)
features = self.extract_features(data, cfg)
model = self.build_model(cfg)
results = self.train_and_eval(model, features, cfg)
self.log_results(results, cfg)
return resultsCó 2 implementation:
- ClassicalPipeline: extract features → StandardScaler → fit sklearn model → evaluate
- DeepLearningPipeline: wrap vào
EmotionDataModule→ PyTorch LightningTrainer→ evaluate
Feature Caching — giải pháp tốc độ
Vấn đề: với ~5000 audio files, mỗi lần run phải trích xuất đặc trưng lại từ đầu — mất 10–30 phút. Giải pháp: cache 2 tầng.
Disk cache (.npy files) cho spectral features: lần đầu tiên chạy mất thời gian, các lần sau load từ disk trong vài giây. Cache key = hash của config params.
In-memory cache (float16 tensors) cho SSL models: HuBERT inference cực kỳ tốn kém, không thể tái tính mỗi batch. Giải pháp: precompute toàn bộ dataset một lần, giữ trong RAM dưới dạng float16 (giảm 2x memory so với float32).
class InMemoryCache:
def __init__(self):
self._cache: dict[str, torch.Tensor] = {}
def get_or_compute(self, key, compute_fn):
if key not in self._cache:
result = compute_fn()
self._cache[key] = result.half() # float16
return self._cache[key].float()Data Augmentation
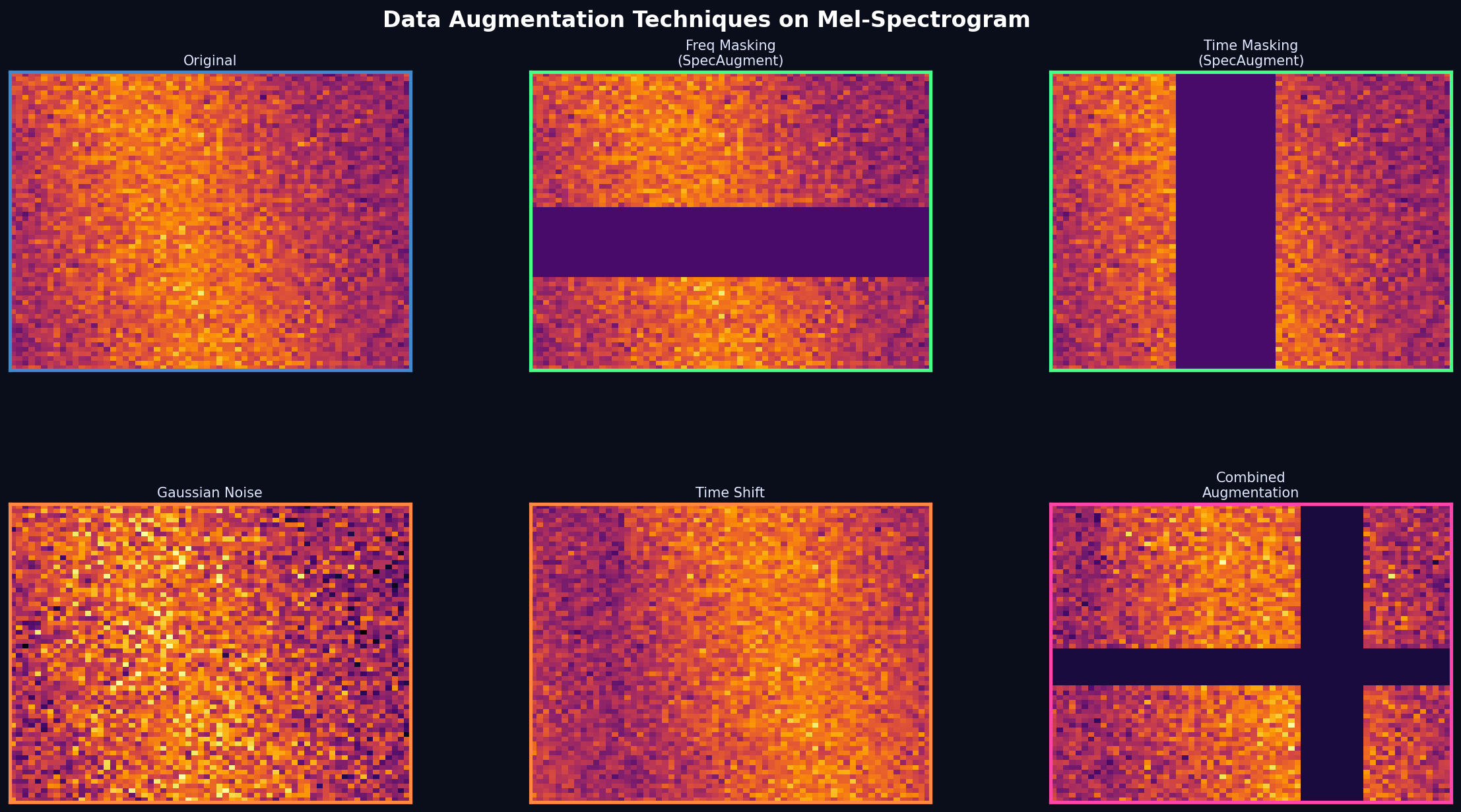
Augmentation ở 2 tầng:
Spectrogram-level (nhanh, áp dụng trong DataLoader):
- SpecAugment (Park et al. 2019): mask ngẫu nhiên các dải tần số và đoạn thời gian
- Gaussian Noise: thêm nhiễu σ=0.02 để regularize
- Time Shift: dịch cyclic ≤10% độ dài
Waveform-level (phong phú hơn, áp dụng offline):
- Speed Perturbation: thay đổi tốc độ ±10%
- Pitch Shift: thay đổi cao độ ±2 semitones
- SNR Noise: thêm noise với SNR ngẫu nhiên 10–40dB
Hydra Configuration System
Mỗi pipeline là một combination config, ví dụ:
# Run BiLSTM với Log-Mel + augmentation
python train.py feature_extraction=logmel model=bilstm augmentation.enabled=true
# Batch run tất cả pipelines
python run_pipelines.py --aug-mode both
# So sánh kết quả
python compare.py --compare-augHydra cho phép override bất kỳ param nào từ CLI mà không cần sửa code — rất quan trọng cho reproducibility trong nghiên cứu.
PyTorch Lightning Integration
Lightning tự động hóa boilerplate training: gradient accumulation, learning rate scheduling, early stopping, checkpointing. Chỉ cần định nghĩa training_step và configure_optimizers:
class RNNModule(pl.LightningModule):
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.cross_entropy(logits, y)
self.log("train/loss", loss)
return loss
def configure_optimizers(self):
return Adam(self.parameters(), lr=self.lr)Kết luận
Xây dựng một framework ML có hệ thống đòi hỏi tư duy thiết kế cẩn thận: modularity, caching, reproducibility, và ease of experimentation. Các kỹ thuật tôi đã áp dụng — Strategy pattern, 2-tier caching, Hydra config, Lightning training — đều có thể tái sử dụng cho nhiều bài toán ML khác.
Ở bài tiếp theo, tôi sẽ đi sâu vào kết quả benchmark và phân tích tại sao BiLSTM + Log-Mel vượt trội hơn các phương pháp khác.