Mô tả dự án
Hệ thống chatbot hỏi đáp thông minh chuyên biệt cho Trường Đại học Quốc tế – ĐHQG-HCM, giúp sinh viên tra cứu quy chế học vụ, kỷ luật, học bổng và các chính sách của nhà trường một cách chính xác và nhanh chóng.
Kiến trúc nổi bật:
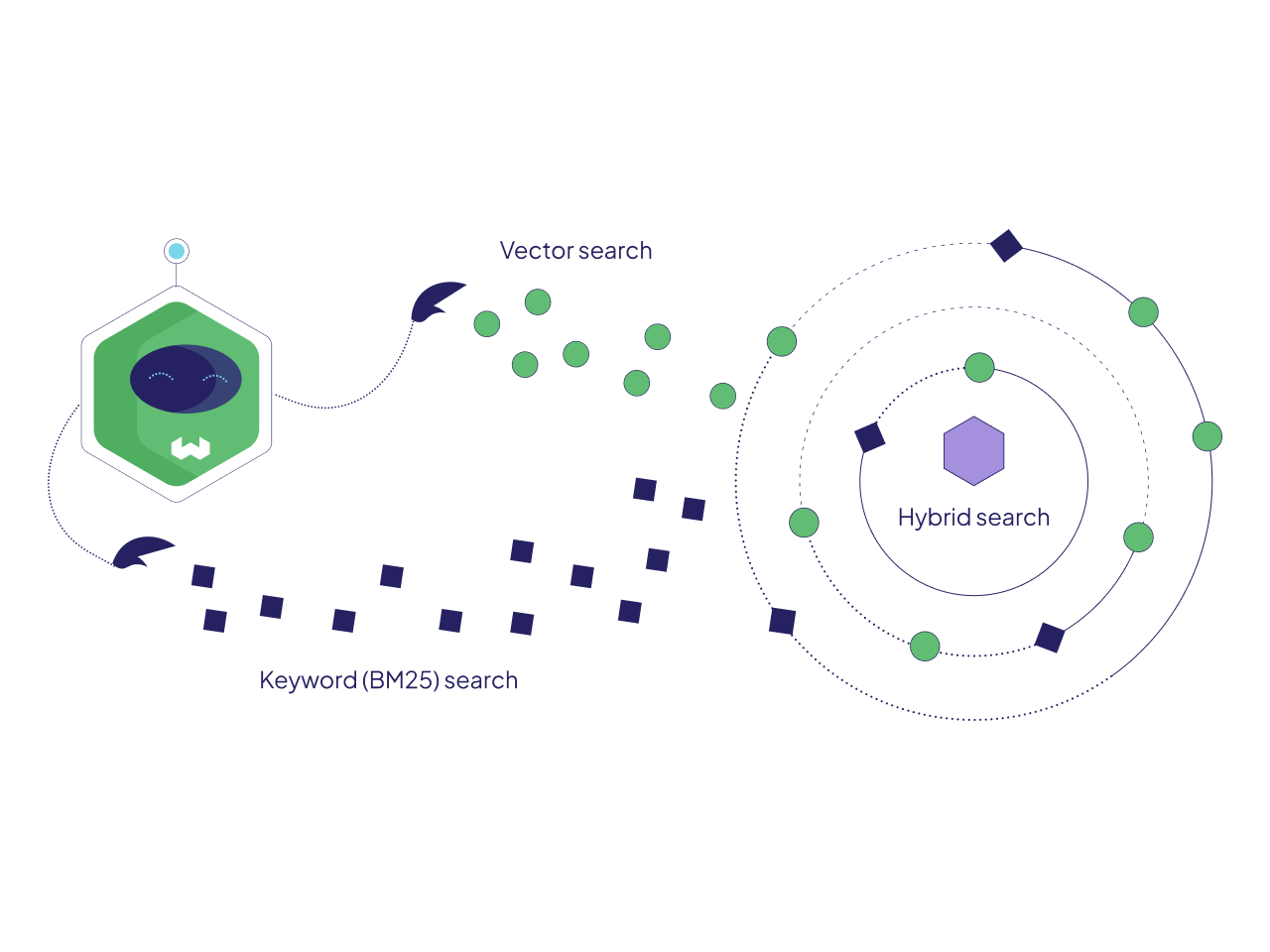
- Hybrid Search: Kết hợp Dense Retrieval (Qdrant vector DB, 768 chiều) và Sparse Retrieval (BM25) để tối đa độ bao phủ tài liệu
- Reciprocal Rank Fusion (RRF, k=60): Hợp nhất hai danh sách ranking mà không cần học tham số
- Cross-Encoder Reranking: Mô hình AITeamVN/Vietnamese_Reranker chấm điểm lại từng cặp (query, chunk), kết hợp source diversity tối đa 3 chunk/tài liệu
- Vietnamese-Aware Chunking: Phân đoạn văn bản theo cấu trúc pháp lý (Điều, Chương, Mục) trước khi fallback về sentence-level
- OCR Fallback: Tích hợp Tesseract (vie+eng) để xử lý PDF scan không có embedded text
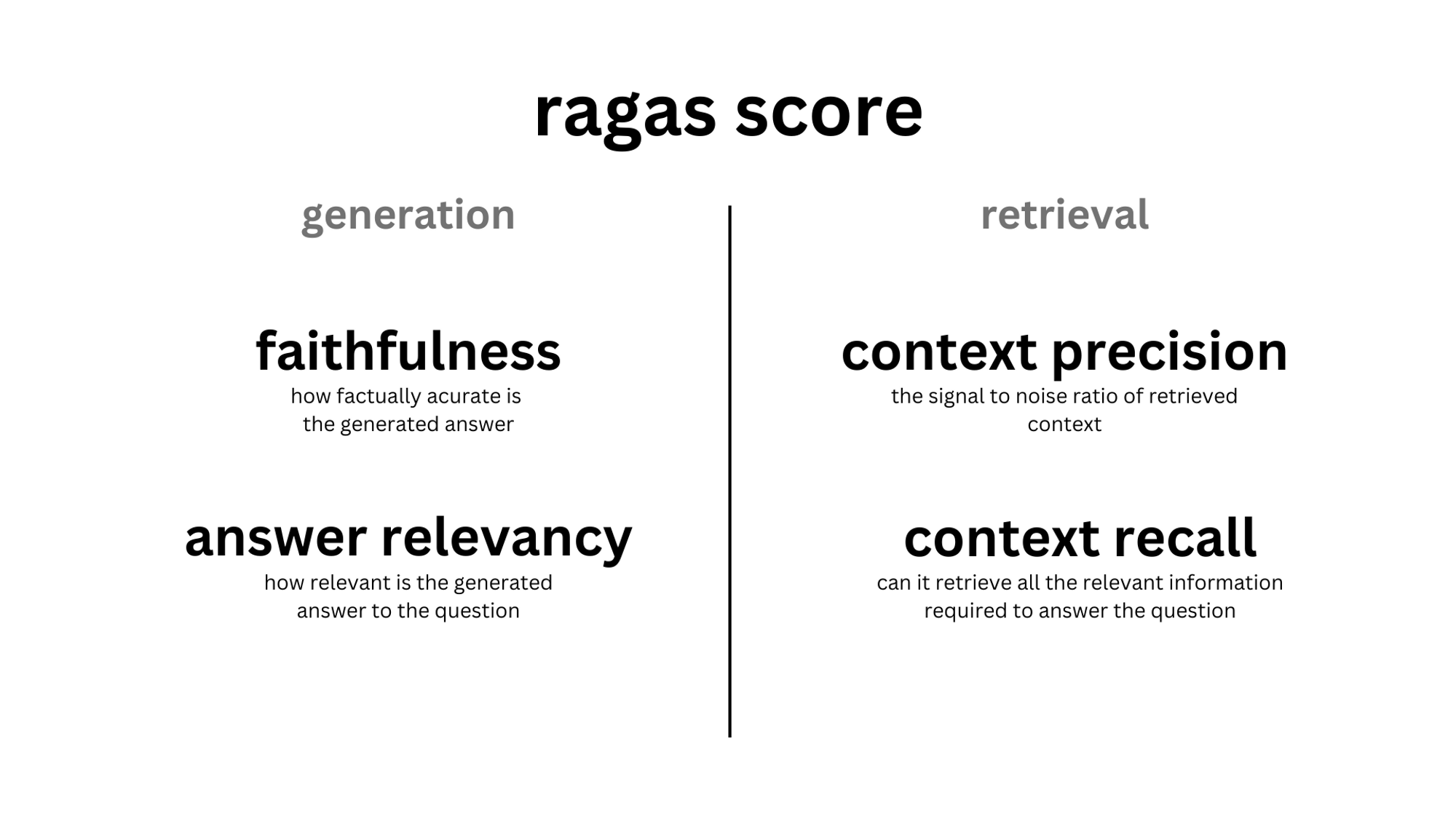
- LLM-as-Judge Evaluation: GPT-4o tự động đánh giá Faithfulness và Answer Relevance trên 134 câu hỏi test
Kết quả đánh giá thực tế (134 queries, 13/04/2026):
- Hit Rate@5: 51.5% | Hit Rate@3: 48.5%
- MRR@5: 0.390 | NDCG@5: 0.411 | MAP@5: 0.376
- Recall@5: 50.0% | Precision@1: 29.1%
- Faithfulness: 80.1% | Answer Relevance: 80.7% | Context Precision: 49.6%
Tech Stack
Hình ảnh dự án
Timeline dự án
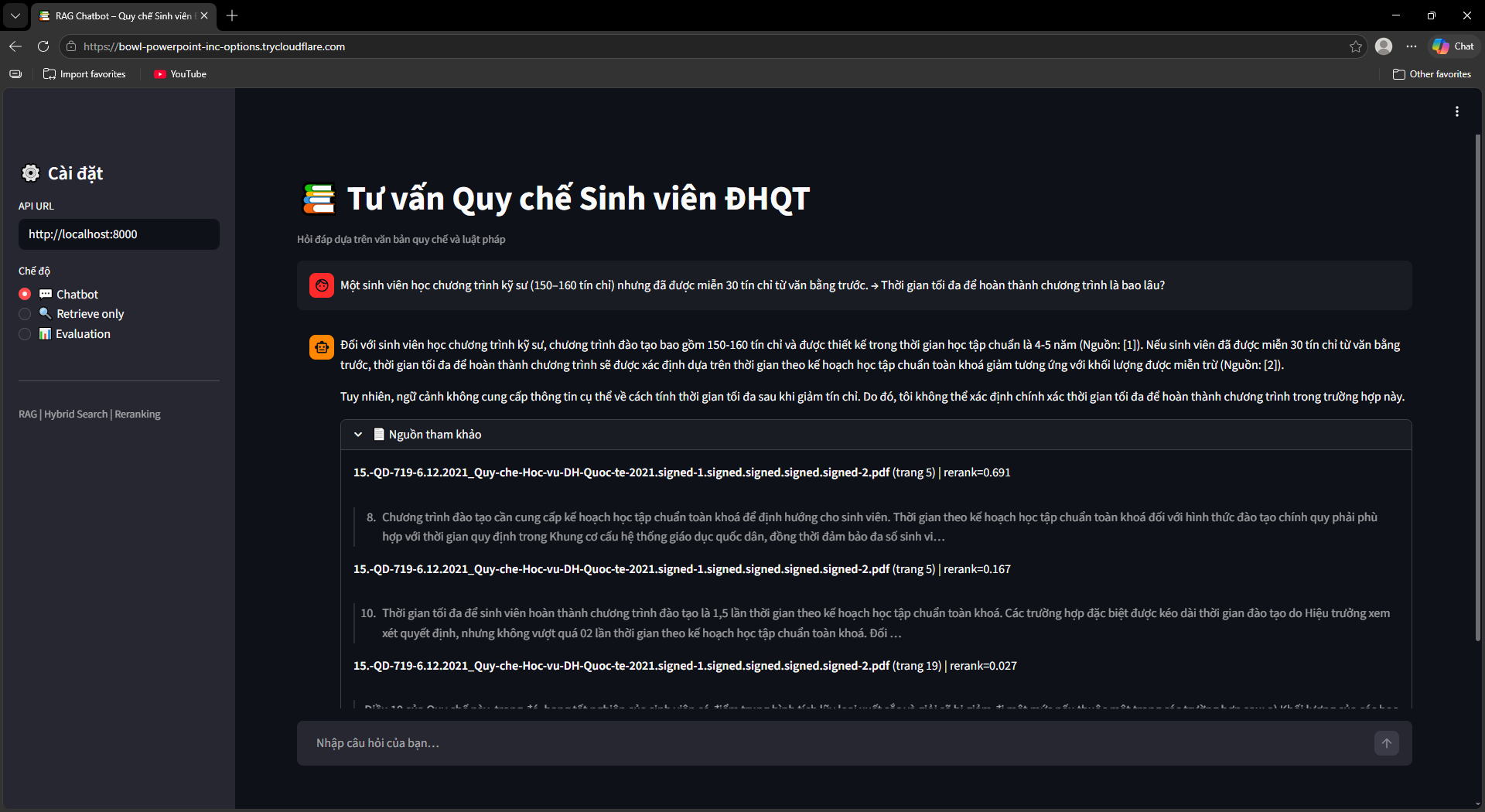
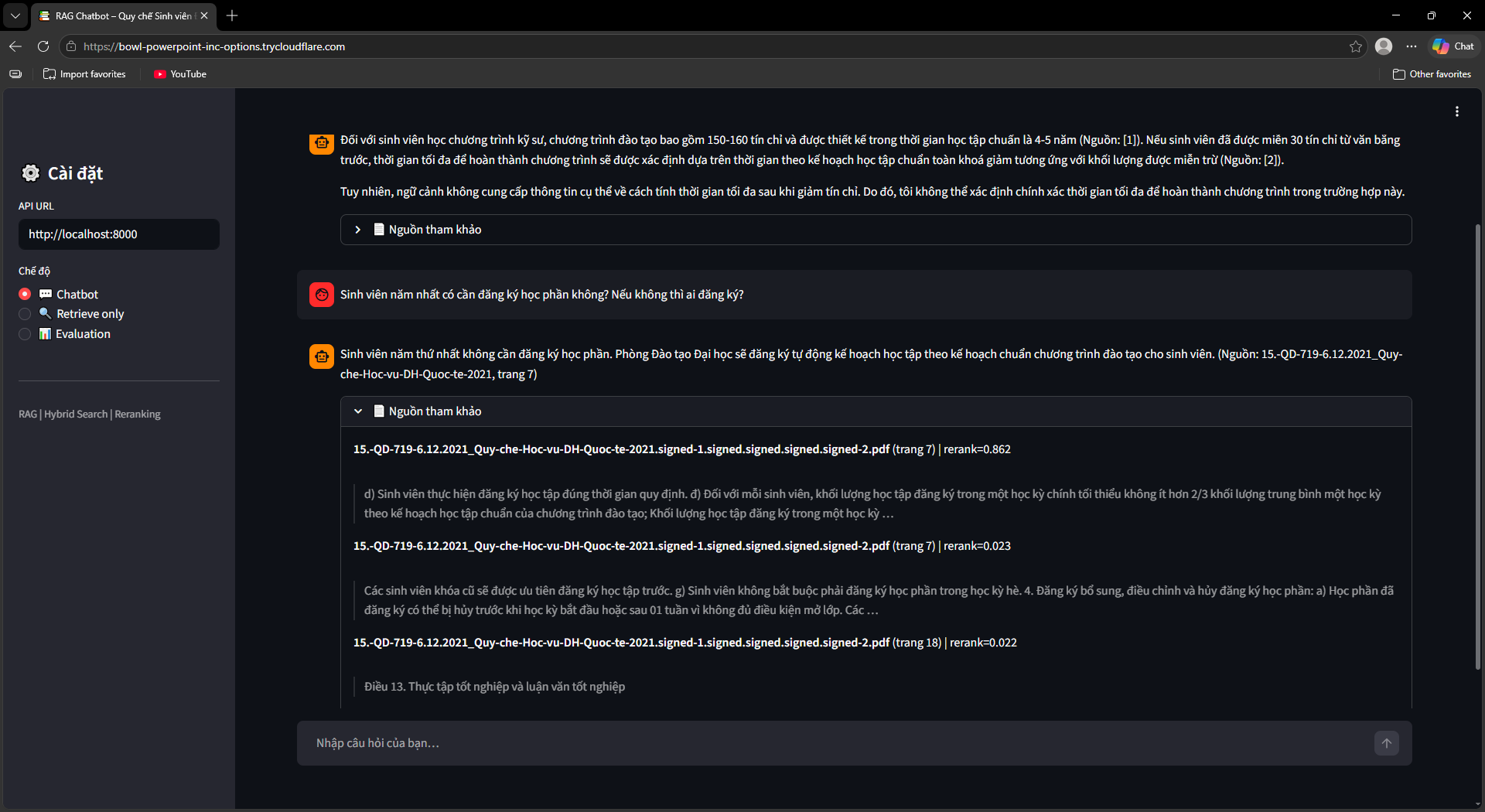
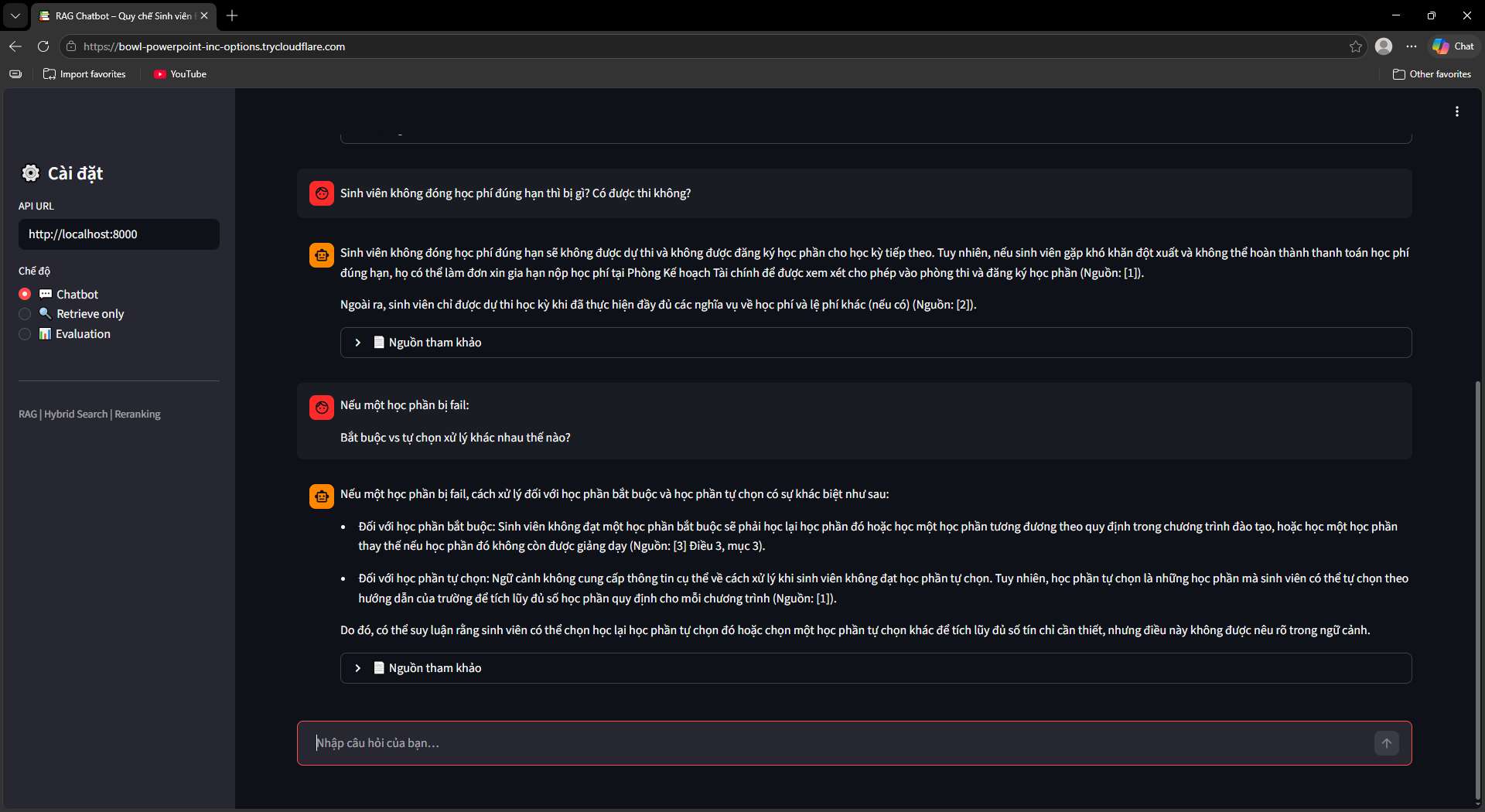
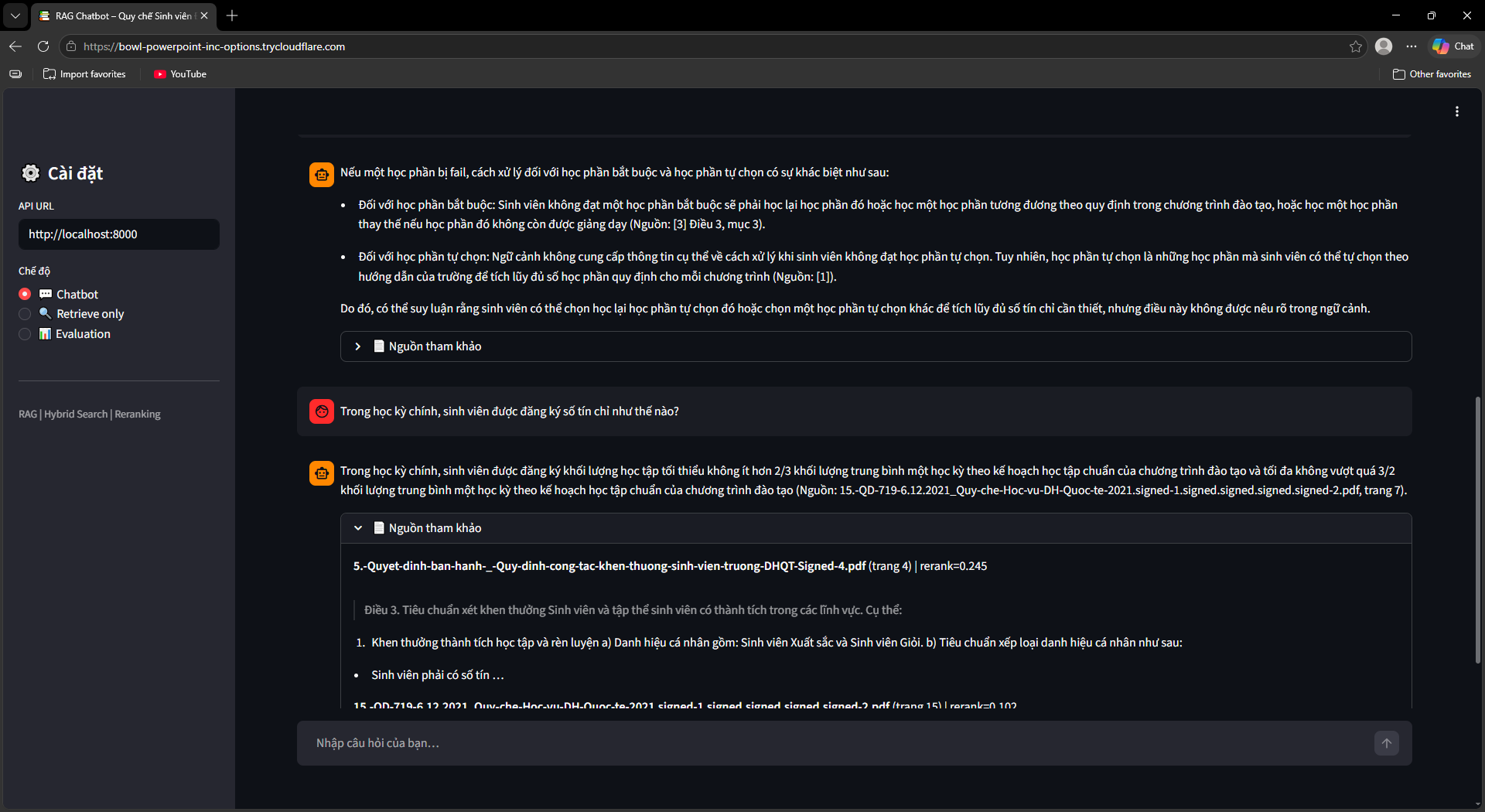
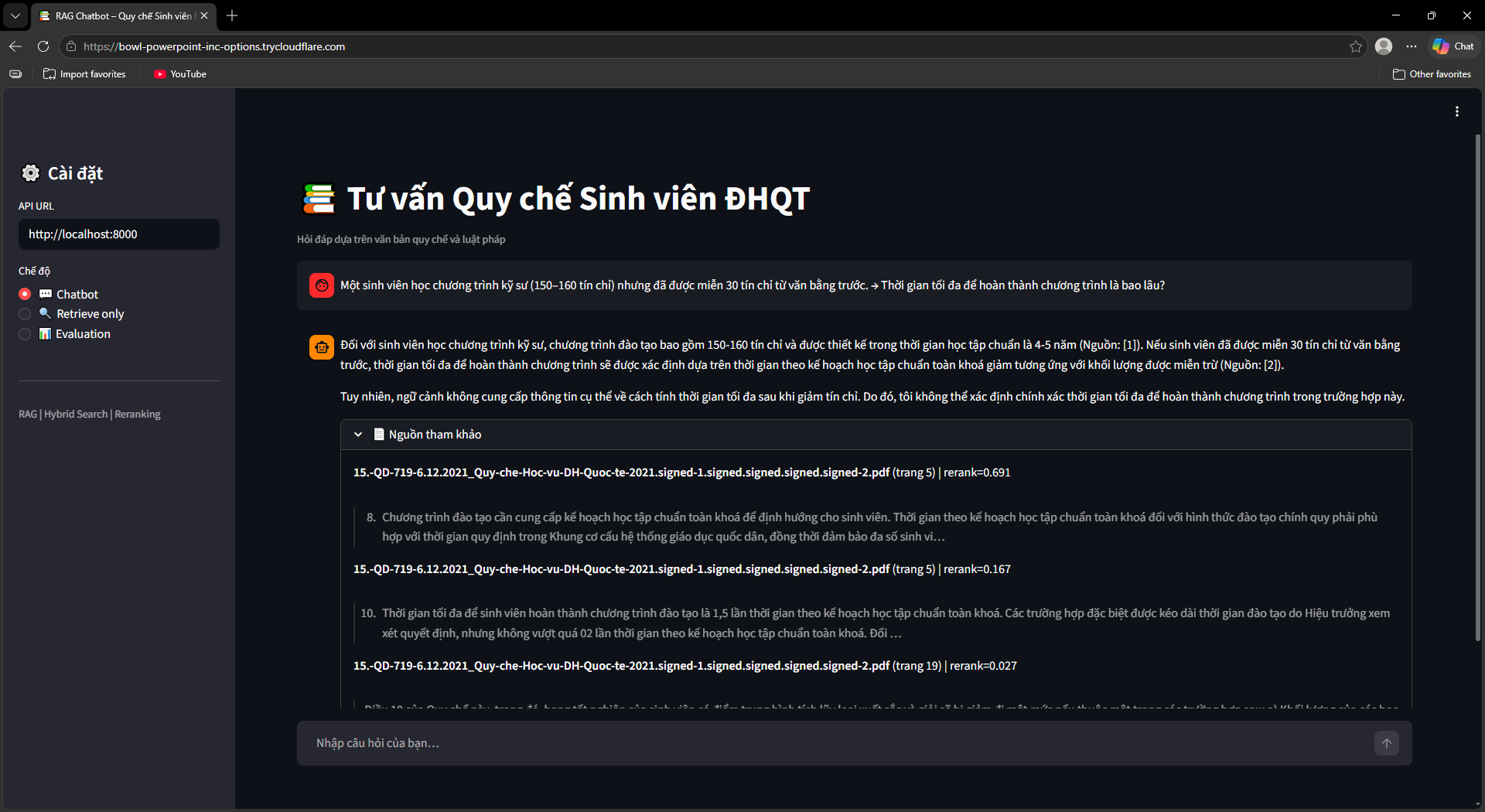
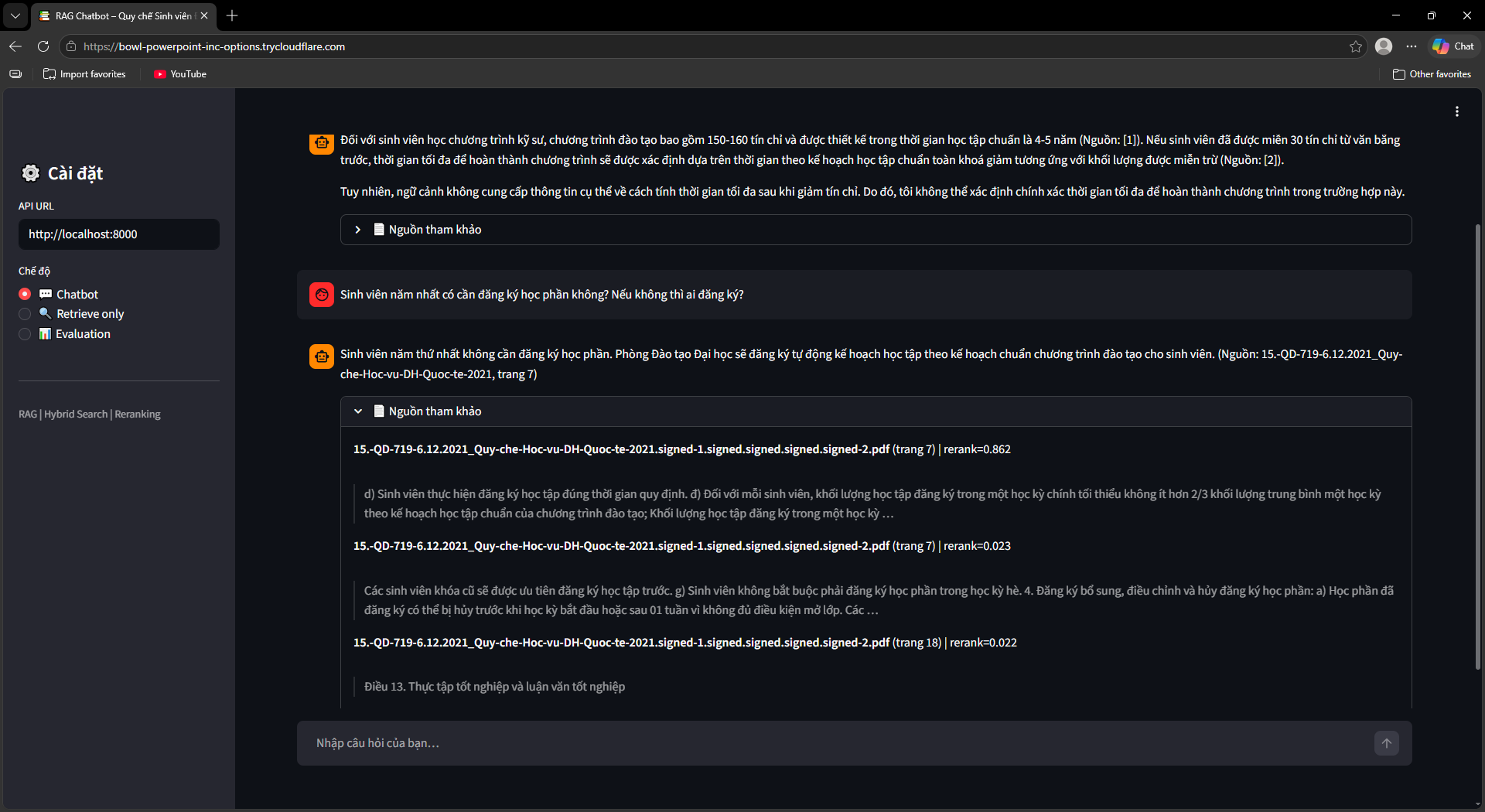
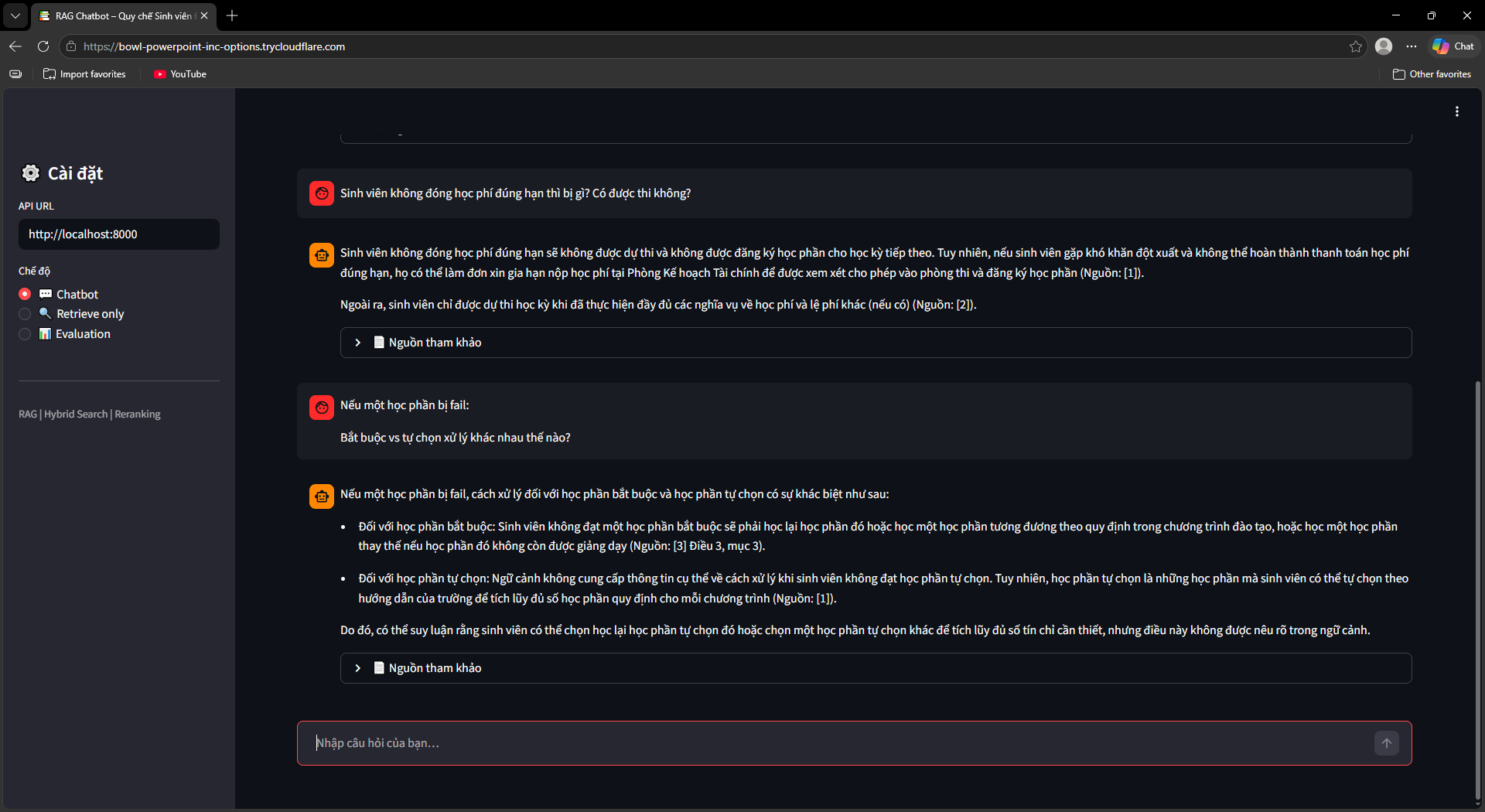
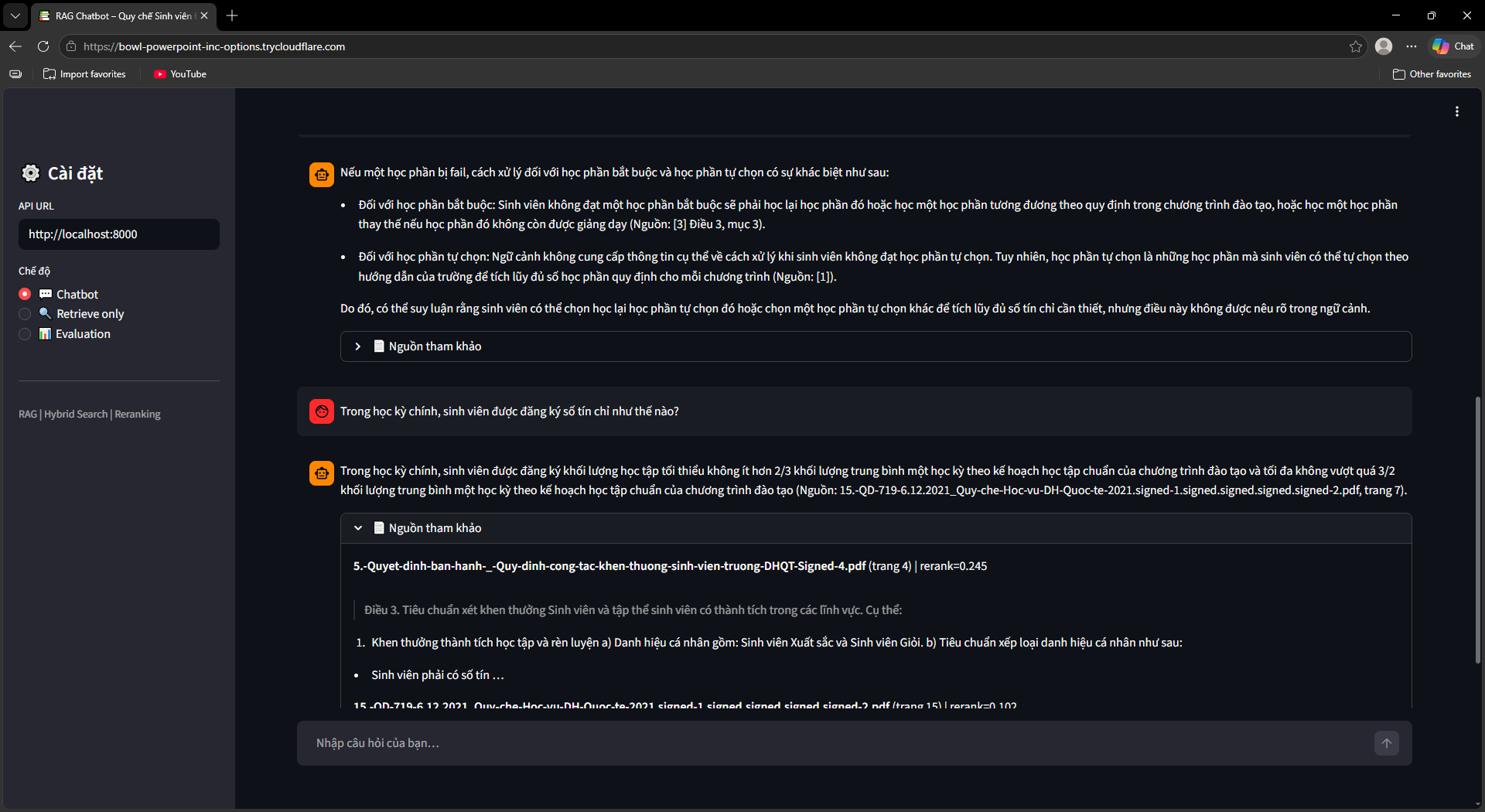
Ra mắt UI, Evaluation & OCR Fallback
Streamlit UI (ui/app.py) với 3 chế độ: Chatbot (hỏi đáp kèm nguồn tài liệu + số trang), Retrieve Only (debug retrieval với RRF score và rerank score), Evaluation Dashboard (chạy và xem kết quả đánh giá).
Bộ đánh giá tự động (src/evaluation/): Sinh 134 câu hỏi test tổng hợp bằng LLM với 4 dạng (factoid, procedural, conditional, multi-hop). Đánh giá 2 pha song song — ThreadPool 8 workers cho RAG pipeline, ThreadPool 30 workers cho LLM-as-Judge calls.
Kết quả đánh giá thực tế (summary_20260413_124932.json):
- Retrieval: Hit Rate@5 = 51.5%, MRR@5 = 0.390, NDCG@5 = 0.411, Recall@5 = 50.0%
- Generation (GPT-4o judge): Faithfulness = 80.1%, Answer Relevance = 80.7%, Context Precision = 49.6%
Fix PDF scan 0 chunks: Thêm OCR fallback dùng Tesseract (lang=vie+eng, 200 DPI) cho 7 file PDF scan. Tự động kích hoạt khi page trích xuất được ít hơn 50 ký tự.
Cross-Encoder Reranking & Source Diversity
Sau khi RRF trả về top-20 candidates, áp dụng thêm tầng reranking để chọn 4 chunks tốt nhất đưa vào LLM:
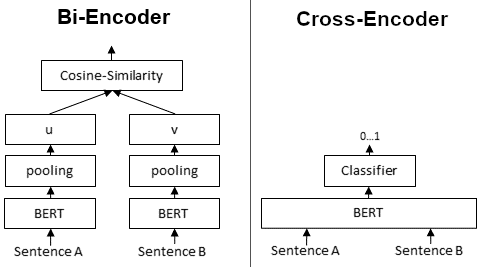
Cross-Encoder Reranking (reranker.py): Dùng AITeamVN/Vietnamese_Reranker — mô hình cross-encoder tiếng Việt chấm điểm trực tiếp từng cặp (query, chunk). Khác biệt với bi-encoder: cross-encoder nhìn đồng thời cả query lẫn document nên chính xác hơn nhiều, chỉ chậm hơn về tốc độ.
Deduplication: Loại bỏ chunks trùng lặp theo chunk_id và 50 ký tự đầu của text.
Source Diversity: Giới hạn tối đa 3 chunks từ cùng một tài liệu nguồn, tránh câu trả lời bị dominated bởi một văn bản duy nhất.
Cũng hỗ trợ Cohere Reranker như alternative qua config (reranking.provider = "cohere").
Output cuối: top_k=4 chunks với đầy đủ rrf_score và rerank_score để hiển thị trong UI.
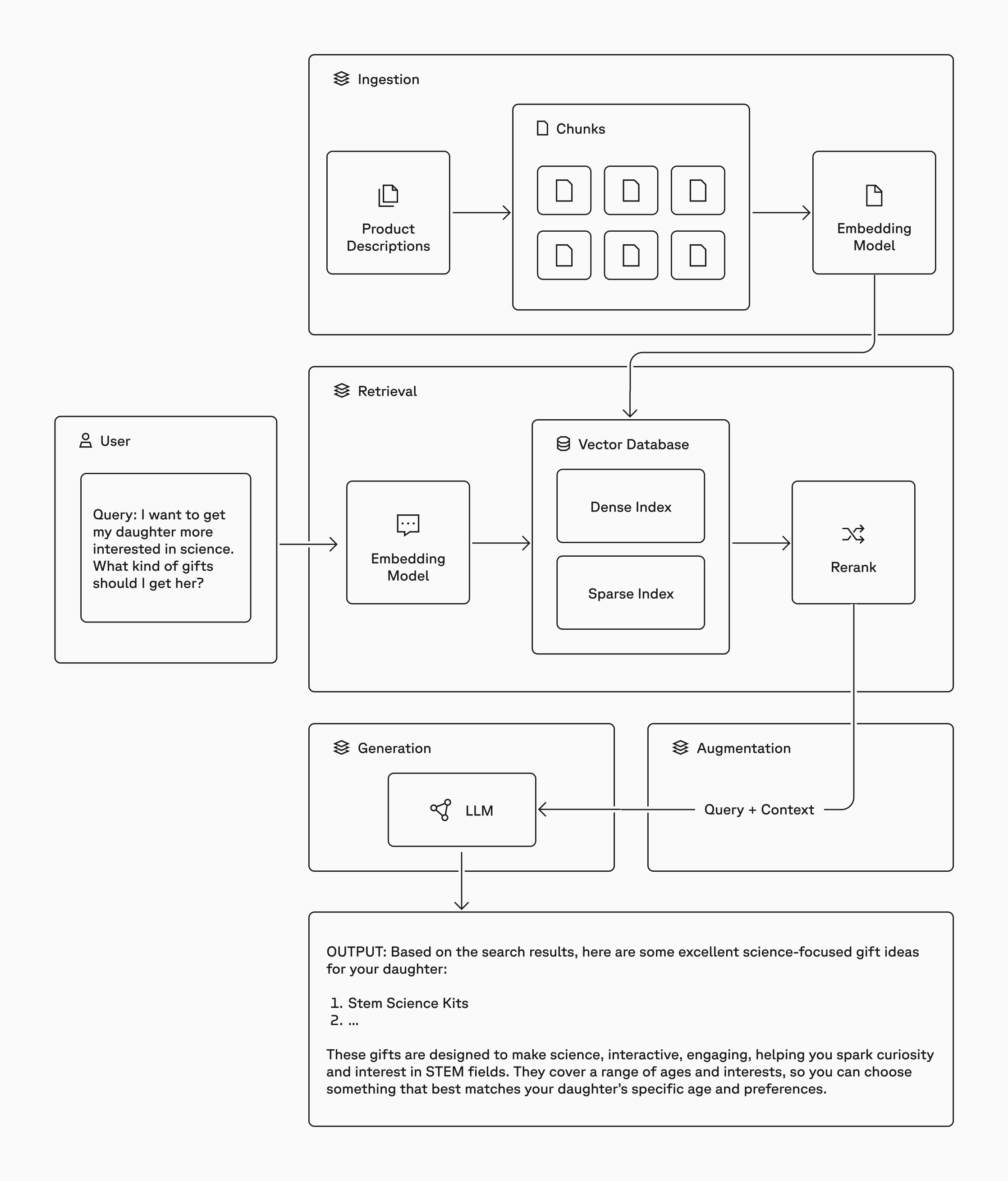
Hybrid Search + Reciprocal Rank Fusion
Triển khai hai nhánh tìm kiếm song song cho mỗi câu hỏi:
Dense Retrieval (vector_store.py): Embed query bằng vietnamese-bi-encoder, tìm top-20 chunks gần nhất trong Qdrant theo cosine similarity. Mạnh với câu hỏi ngữ nghĩa, paraphrase.
Sparse Retrieval (bm25_retriever.py): Tokenize query bằng underthesea, tính BM25 score trên toàn bộ corpus, lấy top-20. Mạnh với từ khóa chính xác, mã điều khoản (Điều 5, Quyết định 719...).
RRF Fusion (hybrid_retriever.py): Hợp nhất bằng Reciprocal Rank Fusion — score(d) = tổng 1/(k + rank_i(d)) với k=60. Không cần learned weights, robust với cả hai loại query. Dedup theo chunk_id, giữ top-20 kết quả hợp nhất.
Kết quả: Hybrid vượt trội cả Dense-only lẫn BM25-only trên bộ test nội bộ, đặc biệt với câu hỏi multi-hop và conditional.
Xây dựng Indexing Pipeline (3 bước)
Bước 1 — Parse PDF (01_parse_chunk.py): Dùng PyMuPDF trích xuất text từng trang. Áp dụng Vietnamese legal-aware chunking: ưu tiên tách theo header pháp lý (Điều X, Chương X, Mục X) trước khi fallback về sentence-level chunking. Cấu hình chunk_size=800 ký tự, overlap=150. Output: 35 file JSONL với mỗi record gồm chunk_id, source, page, text.
Bước 2 — Embedding & Indexing (02_embed_index.py): Embed toàn bộ chunks bằng bkai-foundation-models/vietnamese-bi-encoder (768 chiều, batch_size=32). Upsert vào Qdrant collection "rag_docs" với cosine distance. Hỗ trợ cả local và OpenAI embeddings qua config.
Bước 3 — BM25 Sparse Index (03_bm25_index.py): Tokenize tiếng Việt bằng underthesea, xây BM25Okapi index (k1=1.5, b=0.75), pickle thành bm25.pkl (~2.3 MB).
Tổng kết: 700+ chunks từ 28 file PDF có text (7 file scan chờ OCR).
Khởi động dự án & thu thập dữ liệu
Xác định bài toán: sinh viên ĐHQT cần tra cứu quy chế nhanh nhưng các văn bản pháp lý dài, phức tạp và phân tán trên nhiều tài liệu.
Thu thập 35+ tài liệu PDF chính thức từ nhà trường gồm: quy chế học vụ, quy chế công tác sinh viên, quy định kỷ luật, chính sách học bổng, nội quy ký túc xá, quy định ban cán sự lớp, luật quốc gia liên quan... Tổng dung lượng ~15 MB, phân loại vào 7 danh mục.
Phát hiện vấn đề quan trọng: 7 trong số 35 file là PDF scan (ảnh), không có embedded text — cần bổ sung OCR fallback sau.
Thiết kế kiến trúc tổng thể: Hybrid Search (Dense + Sparse) → RRF Fusion → Cross-Encoder Reranking → GPT-4o generation, với FastAPI backend và Streamlit frontend.