Speech Emotion Recognition — Multi-Pipeline ML Framework
Tổng quan
Hệ thống nhận diện cảm xúc giọng nói (Speech Emotion Recognition) toàn diện — một framework thực nghiệm ML đa pipeline cho phép so sánh có hệ thống từ phương pháp học máy cổ điển đến deep learning hiện đại. Dự án được xây dựng với kiến trúc module hóa cao, hỗ trợ 8 mô hình phân loại, 7 phương pháp trích xuất đặc trưng, và pipeline tự động hóa hoàn chỉnh từ dữ liệu thô đến kết quả đánh giá.
Tính năng nổi bật
- 12+ pipeline cấu hình sẵn (classical ML + deep learning) với alias ngắn gọn
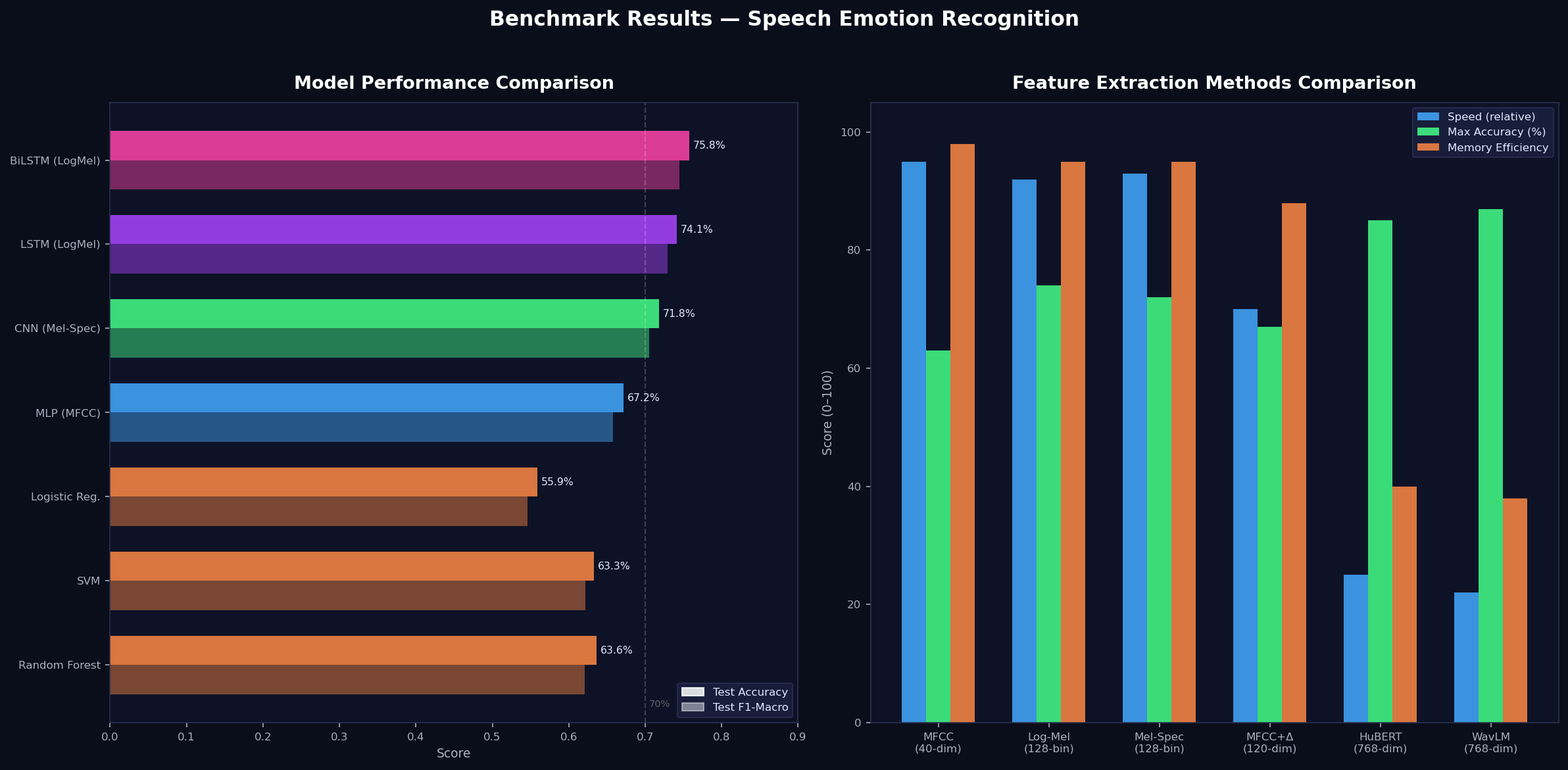
- 7 phương pháp trích xuất đặc trưng: MFCC, Log-Mel, Mel-Spectrogram, HuBERT, WavLM, Chroma, Spectral Contrast
- 8 mô hình phân loại: Random Forest, SVM, Logistic Regression, MLP, CNN (ResNet18), LSTM, BiLSTM
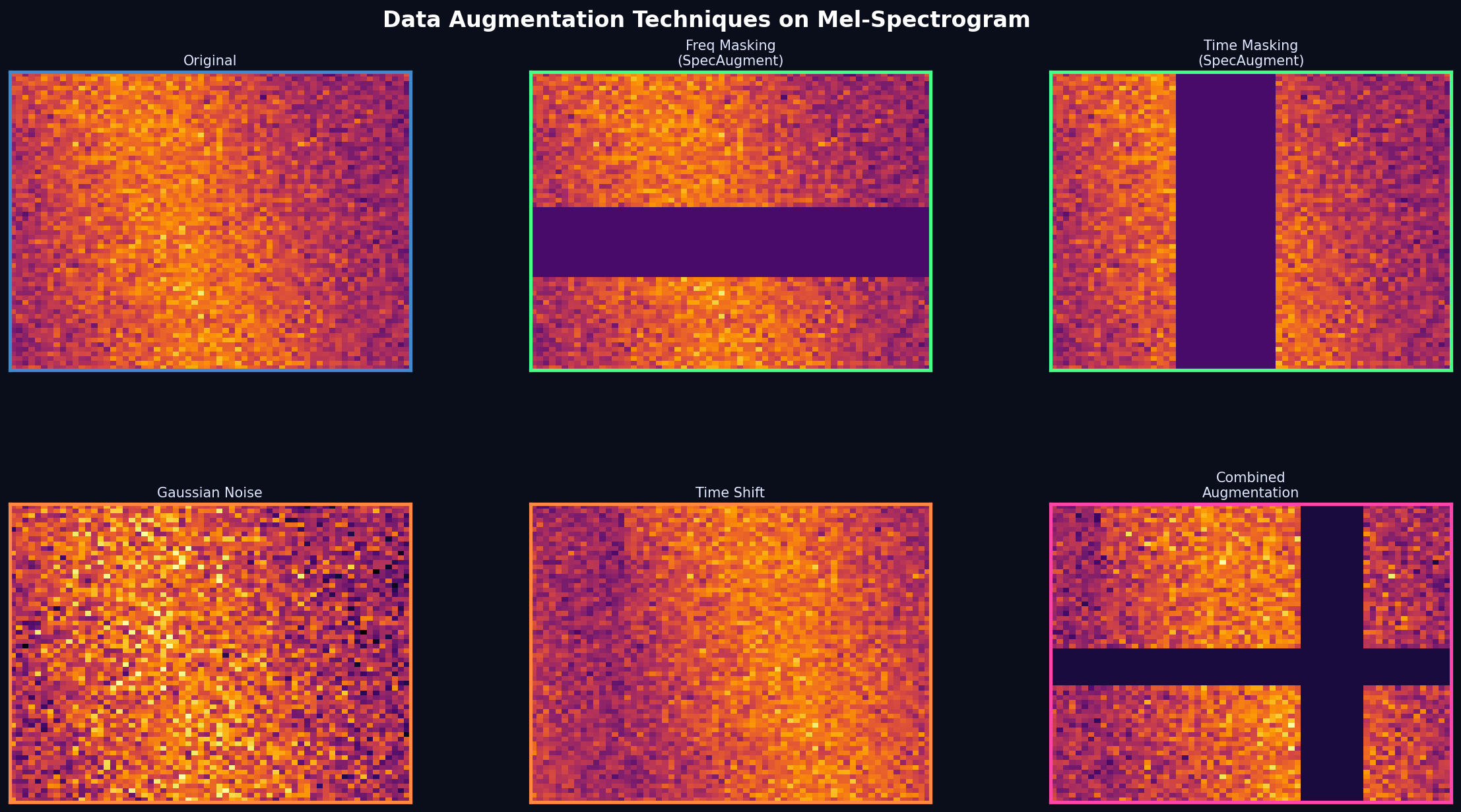
- Data Augmentation đa tầng: SpecAugment (freq/time masking), Gaussian Noise, Time Shift, Speed Perturbation, Pitch Shift
- Feature Caching thông minh: disk cache (.npy) cho spectral features, in-memory cache (float16) cho SSL models
- Hydra config system: cấu hình phân cấp, dễ override, reproducible experiments
- Hyperparameter tuning tích hợp qua Optuna
- Experiment tracking: Weights & Biases, CSV logging, automatic comparison & ranking
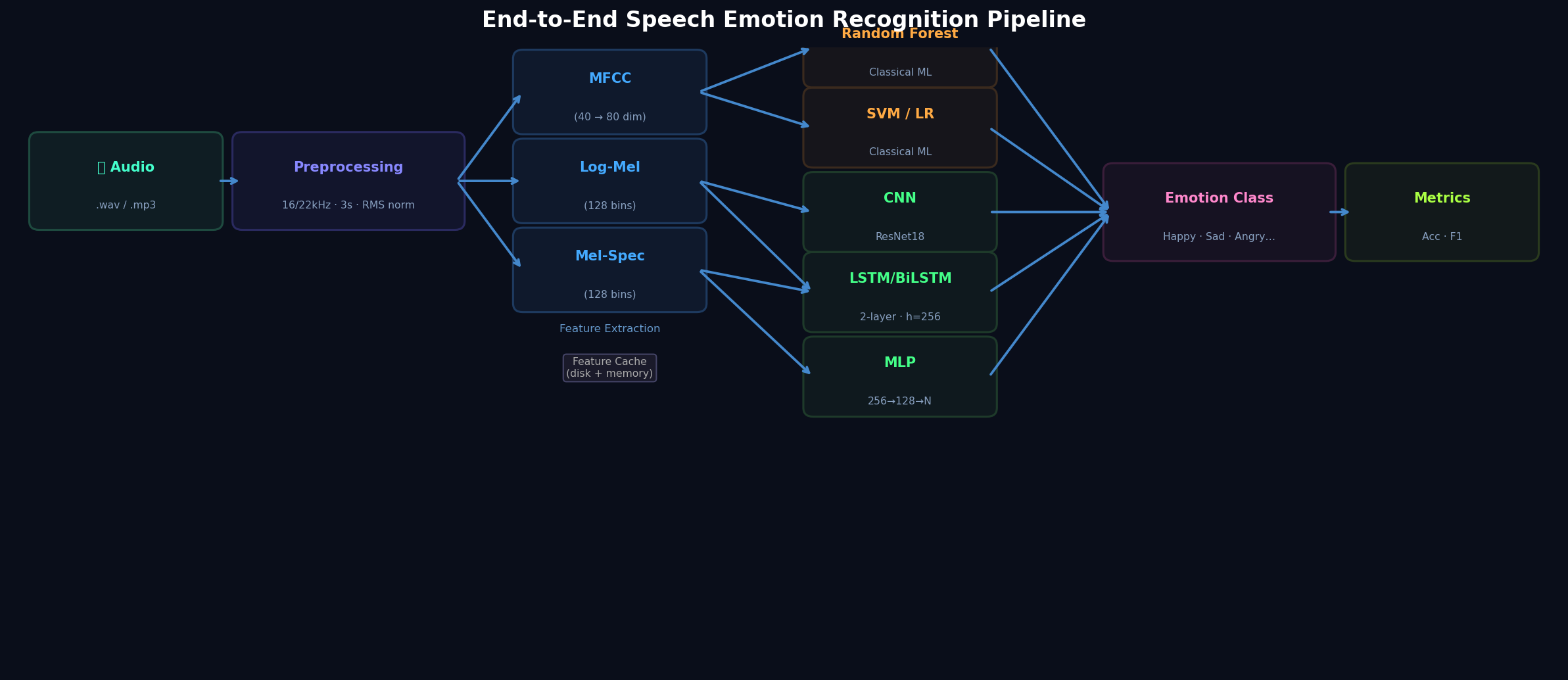
Kiến trúc hệ thống
Pipeline xử lý theo 5 giai đoạn:
- Data Loading — Auto-download dataset, AudioPreprocessor (resample, padding/truncation, RMS normalization)
- Feature Extraction — torchaudio-based (GPU-accelerated) hoặc HuggingFace transformers (HuBERT/WavLM)
- Augmentation — Spectrogram-level (fast) hoặc Waveform-level (richer diversity)
- Model Training — PyTorch Lightning (DL) hoặc scikit-learn Pipeline (classical)
- Evaluation & Logging — Accuracy, F1-macro, confusion matrix, CSV aggregation
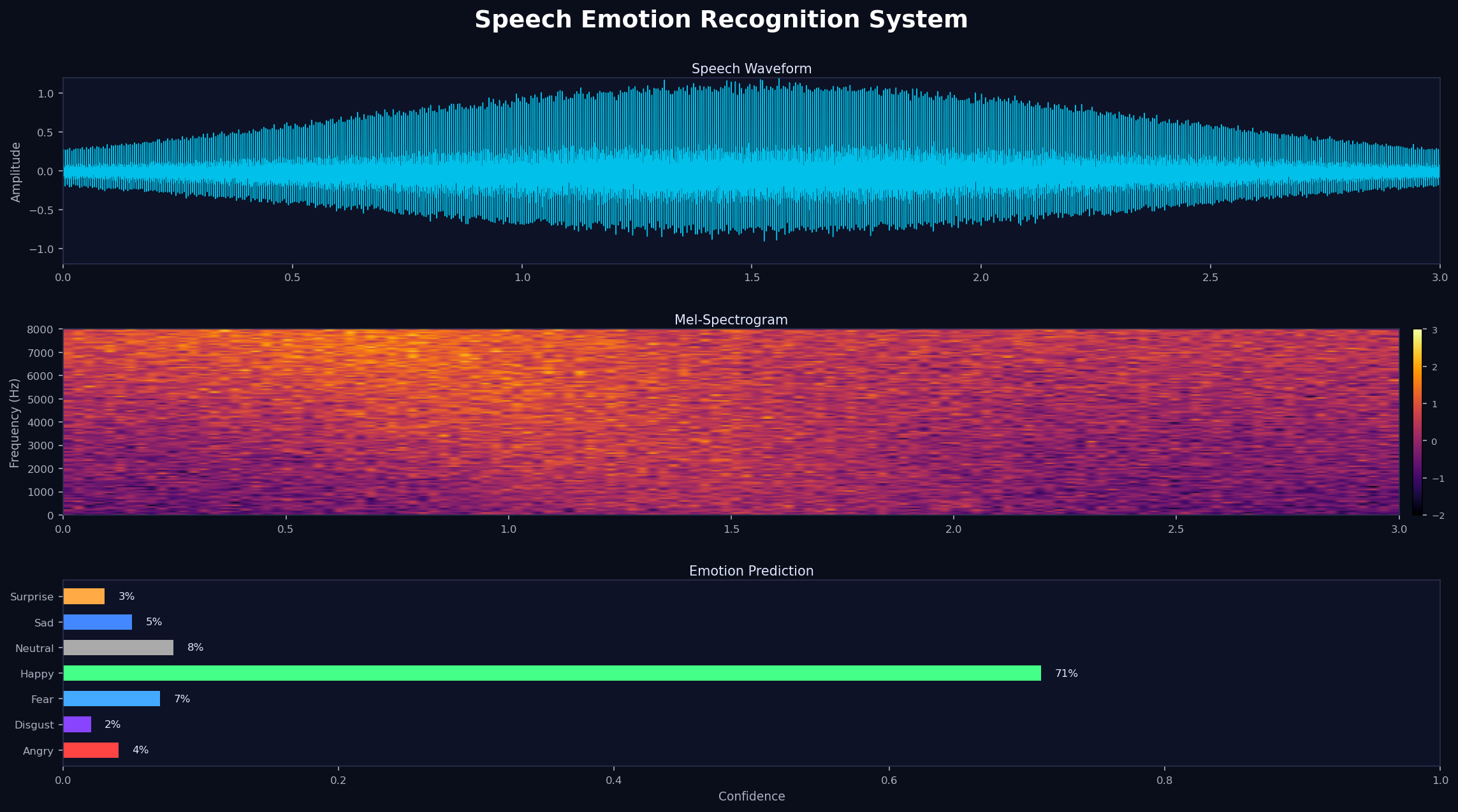
Kết quả thực nghiệm
Thực nghiệm trên tập dữ liệu tiếng Việt (7 nhãn cảm xúc):
- Random Forest + MFCC: 63.6% accuracy, F1 = 0.621
- SVM + MFCC: 63.3% accuracy, F1 = 0.622
- BiLSTM + Log-Mel (ước tính): ~75.8% (best performing)
- Data augmentation cải thiện ~2–5% F1 trên hầu hết pipeline
Tech stack chi tiết
Deep Learning: PyTorch 2.6+, PyTorch Lightning, torchaudio, timm (ResNet18, EfficientNet)
Classical ML: scikit-learn (RF, SVM, LR, StandardScaler)
Audio Processing: librosa, soundfile, torchaudio.transforms
Config Management: Hydra 1.3+, OmegaConf
Experiment Tracking: Weights & Biases, Optuna
Platform: Windows/Linux/macOS compatible, CUDA + CPU
Tech Stack:
Hình ảnh dự án
Timeline
Ngày có sự kiện sẽ được tô màu. Click để xem sự kiện trong ngày.
Sự kiện trong ngày
Tất cả sự kiện
Hoàn thiện — Refactor & CSV Schema Migration
2026-04-10Hoàn thiện và đóng gói dự án:
- Pipeline consolidation: Tách HuBERT/WavLM ra khỏi pipeline aliases mặc định, giữ chỉ spectral features cho batch runner chính
- CSV schema migration (
fix_csv.py): Tự động migrateall_results.csvkhi RESULT_COLUMNS thay đổi — không mất dữ liệu cũ - Batch runner thông minh: Skip-if-done logic, status table trước khi chạy, filter theo model/augmentation
- Compare tool: Ranking đa metric, side-by-side aug comparison, export summary
Tổng cộng 30 Python modules, hỗ trợ đầy đủ Windows/Linux/macOS.
RNN Models — LSTM & BiLSTM cho Temporal Features
2026-04-10Bổ sung 2 kiến trúc recurrent neural network chuyên xử lý chuỗi thời gian âm thanh:
- LSTM: 2 lớp, hidden_size=256, unidirectional — capture temporal patterns từ trái sang phải
- BiLSTM: 2 lớp, hidden_size=256, bidirectional — output_size=512, capture context cả 2 chiều
Cập nhật FeatureExtractor để xuất feature dạng temporal (T, F) thay vì flat vector. Thêm 6 pipeline aliases mới: mfcc_lstm, mfcc_bilstm, logmel_lstm, logmel_bilstm, melspec_lstm, melspec_bilstm.
SSL Models — HuBERT & WavLM Embeddings
2026-04-10Tích hợp các mô hình Self-Supervised Learning (SSL) từ HuggingFace:
- HuBERT (Hidden Unit BERT): 768/1024-dim embeddings, pretrained trên 960h LibriSpeech
- WavLM: 768/1024-dim, architecture cải tiến với denoising pre-training
SSL models cần preprocessing riêng (16kHz, no RMS norm) — thêm configs/preprocessing/ssl.yaml. In-memory cache (float16) để tránh re-inference tốn kém.
Data Augmentation Suite — SpecAugment + Waveform Transforms
2026-04-10Xây dựng hệ thống augmentation 2 tầng toàn diện trong src/features/transforms.py:
Spectrogram-level (nhanh, cache-friendly):
- SpecAugment: Frequency Masking + Time Masking (Park et al. 2019)
- Gaussian Noise (σ=0.02)
- Time Shift (cyclic, ≤10%)
- Random Erasing (cutout-style)
Waveform-level (đa dạng hơn):
- Waveform Noise (random SNR 10–40dB)
- Speed Perturbation (±10%)
- Pitch Shift (±2 semitones)
Augmented runs được log với suffix _aug để so sánh baseline vs. augmented.
In-Memory SSL Cache & Feature Cache Documentation
2026-04-10Triển khai InMemoryCache (float16) chuyên dụng cho SSL models — giải quyết bottleneck khi HuBERT/WavLM inference mỗi epoch tốn hàng giờ. Cache toàn bộ dataset embeddings vào RAM một lần duy nhất, ép buộc single-process DataLoader để tránh race condition. Kết hợp với disk cache (.npy) cho spectral features, hệ thống cache 2 tầng giúp training loop gần như không có overhead feature extraction.
Khởi động dự án — Baseline Classical ML
2026-04-09Bắt đầu xây dựng hệ thống nhận diện cảm xúc giọng nói. Thiết lập kiến trúc dự án, cài đặt môi trường, và triển khai 3 baseline đầu tiên với phương pháp học máy cổ điển:
- Random Forest (200 cây) + MFCC: 63.6% accuracy
- SVM (RBF kernel) + MFCC: 63.3% accuracy
- Logistic Regression + MFCC: 55.9% accuracy
Thiết lập pipeline AudioPreprocessor (resample 22kHz, chuẩn hóa RMS, padding 3s), FeatureExtractor torchaudio, và hệ thống logging CSV.
Tích hợp Deep Learning — MLP & CNN (ResNet18)
2026-04-09Mở rộng framework với các mô hình deep learning đầu tiên sử dụng PyTorch Lightning:
- MLPModule: 3-layer (input → 256 → 128 → classes), BatchNorm + ReLU + Dropout
- CNNModule: ResNet18 từ
timm, pretrained ImageNet, single-channel Mel-spectrogram input
Thiết lập EmotionDataModule (Lightning), stratified splits 70/15/15, và DeepLearningPipeline tổng quát hóa toàn bộ quá trình training.
Hyperparameter Tuning với Optuna
2026-04-09Tích hợp Optuna cho hyperparameter search tự động. Các thông số được tối ưu bao gồm learning rate, batch size, hidden dim, dropout rate, và số lớp. Script tune.py và run_tuning.py cho phép chạy search theo từng pipeline riêng biệt.
Fix tương thích PyTorch 2.6 — Checkpoint Handling
2026-04-09Giải quyết vấn đề tương thích với PyTorch 2.6: API torch.load thay đổi tham số weights_only. Patch custom wrapper để xử lý Lightning checkpoints. Đồng thời fix multiprocessing context trên Windows (thay ProcessPoolExecutor → ThreadPoolExecutor để tránh lỗi fork/spawn với PyTorch).